Traditional Statistics versus Machine Learning. What’s the Difference?
Since machine learning is a hot topic, we thought it useful to clarify the difference between machine learning and traditional statistics as applied to supply chain planning (SCP).
Both technologies help you better understand data and are classified as analytics, but each takes a very different approach. By understanding the difference, we see that they are complementary. And because they are complementary, we see that the ideal approach is to combine the two technologies in a way that plays to each other’s strengths.
Traditional statistics has been around for centuries, preceding computers. It therefore has relied on small samples of data and makes prior (or “a priori”) assumptions about data. A priori means “derived by reasoning from self-evident propositions” (Miriam Webster Dictionary). So traditional demand forecasting statistical analysis is preprogrammed with the “self-evident proposition” that past demand periods are a good predictor of demand in future periods.
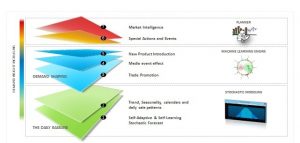
Therefore traditional statistics is about analyzing and summarizing data, and suited to processing lesser amounts of linear, repeatable data to find a solution. It’s very useful in environments where data, and the relationships between the data, are relatively stable. It is still by far the most commonly used methodology and continues to be good for mid to long term forecasting based on prior sales history, where a few hundred or even fewer data points may generate a reasonable forecast.
But three things have changed in recent years: the availability of new data, the advent of increasingly cheaper and faster computing power, and growing demand volatility caused by the increased influence of demand drivers such as new product introductions, social media and promotions. Increased demand volatility has created the need for new techniques to forecast demand. Increased data and computer power offers the opportunity to address it.
Machine learning relies heavily on the availability of that data and computing power. Rather than make a priori assumptions, machine learning enables the system to learn from data. Rather than following preprogrammed algorithms, it uses the data to build and constantly refine a model for making predictions. It helps understand demand volatility by capturing and modeling attributes that shape the demand. It learns from the data, and modifies operations accordingly.
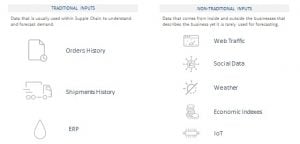
For example, a machine learning system turned loose on web data for new products can learn which demand indicators—such as page hits, specification downloads, time on site—are most reliable, and can also update its model as consumer behaviors change. This lets companies take advantage of data signals generated closer to the customer, like points of sale and social media channels.
And this is why machine learning has become such as hot topic in supply chain planning. In an environment where demand volatility is the number-one issue for most supply chains executives, it can be extremely difficult to create a good forecast. But with a volume of constantly changing data streaming down the pipes, machine learning “does extraordinarily well—and will get better at—relentlessly chewing through any amount of data in every combination of variables,” says McKinsey & Company in a recent article on retail replenishment.
And machine learning can also forecast demand based not just on historical sales data, but by accounting for “other influencing parameters: internal factors such as advertising campaigns and store-opening times, and external factors such as local weather and public holidays,” adds McKinsey. For example, with its more granular calculations, “retailers can determine the effect of each parameter on each SKU in each store (and in each distribution center, where relevant) on a daily basis.”
Another way to think about the difference between the two approaches is to consider machine learning as employing inductive reasoning while traditional statistics employs deductive reasoning. To illustrate, I’ll reach back to an explanation from a book I read almost 40 years ago, Zen and the Art of Motorcycle Maintenance. In it, the author Robert Pursig uses diagnosing problems with his motorcycle to explain the difference.
“Inductive inferences start with observations and arrive at general conclusions. For example, if the cycle goes over a bump and the engine misfires, and then goes over another bump and the engine misfires, and then goes over another bump and the engine misfires, and then goes over a long smooth stretch of road and there is no misfiring, and then goes over a fourth bump and the engine misfires again, one can logically conclude that the misfiring is caused by the bumps. That is induction: reasoning from particular experiences to general truths.
“Deductive inferences do the reverse. They start with general knowledge and predict a specific observation. For example, if, from reading the hierarchy of facts about the machine, the mechanic knows the horn of the cycle is powered exclusively by electricity from the battery, then he can logically infer that if the battery is dead the horn will not work. That is deduction.”
In a multi-channel/multi-echelon landscape, the ability to consume and leverage ever-increasing amounts of data clearly favors using machine learning more often to sense demand and to adapt supply to shifting consumption and replenishment needs. Statistical techniques tied to a priory deduction usually can’t readily make heads or tails of this data. Machine learning can, and in a highly automated manner. This also frees planners to focus on managing exceptions, think forward, and apply their knowledge of the business.
But because they are complementary, the ideal approach is to combine the two technologies in a way that plays to each of their strengths. For longer term forecasting, capturing trends and seasonality, statistical and stochastic demand models can perform a solid job. Where we are trying to explain shorter-term variations and inferring outcomes by understanding many sources of data, machine learning offers a unique advantage. This data and visibility can come from promotions, new product launches, social listening, weather patterns or even the Internet of Things (IoT).
And the best combination is to have both technologies embedded in supply chain software, able to work together seamlessly and automatically, giving users the ability to forecast at the most granular level, on different time horizons, without concerning themselves with the underlying technology.